You can Download Chapter 13 Data Concepts Questions and Answers, Notes, 2nd PUC Computer Science Question Bank with Answers Karnataka State Board Solutions help you to revise complete Syllabus and score more marks in your examinations.
Karnataka 2nd PUC Computer Science Question Bank Chapter 13 Data Concepts
2nd PUC Computer Science Data Concepts One Mark Questions and Answers
Question 1.
What is data?
Answer:
Data is a collection of facts, figures or statistics. Data is transformed into meaningful information. It is raw material of information.
Question 2.
What is information?
Answer:
It is processed data with definite meaning. Information gives meaning.
Question 3.
What is the database?
Answer:
A database is a collection of large amounts of related data. In other words, It is a collection of database tables.
Question 4.
What is the field?
Answer:
Each column in a table is identified by a distinct header is called a field.
![]()
Question 5.
What is a record?
Answer:
Collection of related fields (eg- Name, Age, register number, marks)
Question 6.
What is an entity?
Answer:
An entity is a person,place, thing or event for which data is collected and maintained.
Question 7.
What is an instance?
Answer:
Each row of a table is called entity instance.
Question 8.
What is an attribute?
Answer:
An attribute is the characteristic property of an existing entity.
Question 9.
What is domain?
Answer:
A domain describes the set of possible values for a given attribute.
Question 10.
What is a relation?
Answer:
- A relation is defined as a set of tuples that have the same attributes.
- A relation is usually described as a table, which is organized into rows and columns.
Question 11.
What is a table?
Answer:
A table is a collection of data elements organised in terms of rows and columns.
Question 12.
What is normalization?
Answer:
Normalization is the process of reorganizing data in a database by eliminating duplication and ensuring data dependencies.
![]()
Question 13.
What is a key?
Answer:
It is a field in table that uniquely identifies a record (e.g. Register number of a student).
Question 14.
Give the symbol notion for project.
Answer:
The symbol notion for project is ð (pi)
Question 15.
What is data mining?
Answer:
It is the process of discovering interesting knowledge, such as patterns, associations, changes, anomalies from large amounts of data stored in databases.
2nd PUC Computer Science Data Concepts Two Mark Questions and Answers
Question 1.
How database helps us?
Answer:
A database is a collection of logically related data organized in a way that data can be easily accessed, managed and updated. In colleges, student admission details, fee payment details (annual, monthly, late payment), statement of marks etc., can be maintained and various reports can be generated time to time.
Question 2.
How do we get data?
Answer:
Data means collected facts, figures and statistics. The data may be in the form of letter, symbols, numbers, images, videos and sound. It can be collected from various sources inside and outside of an organization or any part of universe.
Question 3.
Name the data types supported by DBMS?
Answer:
The various data types supported by DBMS are integer, single’precision, double precision, character, string, memo, index, currency; date and text fields.
![]()
Question 4.
What is generalization?
Answer:
Generalization is the process of taking the union of two or more lower level entity sets to produce a higher-level entity sets. Generalization is a bottom-up approach. For example,
entities savings account and a current account can be generalized to accounts.
Question 5.
What is specialization?
Answer:
It is a top-down approach in which one higher-level entity can be broken down into two lower level entities. For example, entity accounts can be broken down into savings account and current account.
Question 6.
What is the difference between serial and direct access file organization?
Answer:
- In sequential access data is stored at random locations.
- In direct access data is stored at sequential locations.
- Data structure implementing Sequential access is linked list.
- Data structure implementing Direct access is an Array.
Question 7.
Give the advantages of disadvantages of index sequential access method.
Answer:
The advantages of disadvantages of index sequential access method are
Advantages:
- It combines both sequential and direct
- Suitable for sequential access and random access
- Provides quick access to records
Disadvantages:
- It uses special software and is expensive
- Extra time is taken to maintain index
- Extra storage for index files
- Expensive hardware is required
Question 8.
Classify various types of keys used in database.
Answer:
The various types of keys used in database are candidate key, primary key, secondary key, super key and foreign key.
Question 9.
What is relation algebra?
Answer:
Relational algebra is a formal system for manipulating relations. Operands of this algebra are relations (a set of tuples). Operations of this algebra include the usual set operations, and special operations defined Tor relations.
Question 10.
Give an example for relation selection with example.
Answer:
Selection:
Selects tuples from a relation whose attributes meet the selection criteria, which is normally expressed as a predicate. For example, find all employees born after 14th February 2000.
![]()
Question 11.
What is Cartesian product?
Answer:
The Cartesian Product is also an operator that works on two sets. It is sometimes called the CROSS PRODUCT or CROSS JOIN. It combines the tuples of one relation with all the tuples of the other relation.
Question 12.
What is join operation?
Answer:
JOIN is used to combine related tuples from two relations i.e., combines attributes of two relations into one. In its simplest form, the JOIN operator is just the cross product of the two relations.
Question 13.
What is data warehouse?
Answer:
A data warehouse (DW) is a database used for reporting. The data is offloaded from the operational systems for reporting.
Question 14.
What is data mining?
Answer:
It is the process of discovering interesting knowledge, such as patterns, associations, changes, anomalies from large amounts of data stored in databases using pattern recognition technologies as well as statistical and mathematical techniques.
2nd PUC Computer Science Data Concepts Three Mark Questions and Answers
Question 1.
Mention the applications of database.
Answer:
The applications of database are banking, water meter billing, rail and airlines, colleges, credit card transactions, telecommunication, finance/sales, manufacturing and human resources.
![]()
Question 2.
Give the difference between manual and electronic file systems.
Answer:
The difference between manual and electronic file systems.
| Manual File System | Electronic File System |
| 1) Process limited volume of data | 1) process a large volume of data |
| 2) uses paper to store data | 2) use of mass storage devices in computer itself |
| 3) the speed and accuracy is less | 3) more speed and greater accuracy |
| 4) cost of processing is high since more human-oriented | 4) cost of processing less because computer performs repetitive task |
| 5) occupies more space | 5) little space is sufficient |
| 6) Repetitive tasks reduces efficiency and human feel bore and tiredness | 6) Efficiency is maintained throughout and won’t feel bore and tiredness. |
Question 3.
Explain Boyce and Codd form (BCNF).
Answer:
Boyce and Codd form (BCNF):
- When a relation has more than one candidate key, anomalies may result even though the relation is in 3NF.
- 3NF does not deal satisfactorily with the case of a relation with overlapping candidate keys
- BCNF is based on the concept of a determinant.
- A determinant is any attribute on which some other attribute is fully functionally dependent. .
- A relation is in BCNF is, and only if, every determinant is a candidate key.
Examples: Conisder a database table that stores employee information and has the attributes employee_id, first_name, last_name title. In this table, the field employee_id determines first_name and last_name. Similarly, the tuple ( first_name, last_name ) determines employee_id.
Question 4.
Give the different notations for E-R Diagram.
Answer:
the different notations for E-R Diagram
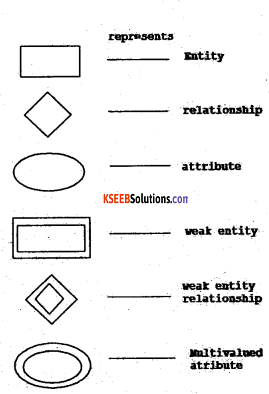
Question 5.
Explain any three components of the E-R diagram.
Answer:
The three main components of the E-R diagram are Entity, Attribute and Relationship.
![]()
Question 6.
What is the relationship? Classify and give an example.
Answer:
A relationship is defined as “an association among entities”. A relationship describe relations between entities and represented using diamond symbol in E-R diagram. There are three types of relationship namely binary relationship, unary relationship and ternary relationship.
1. Binary relationship:
A Binary relationship is the one that links two entities sets e.g. STUDENT-CLASS.
2. Unary Relationship:
An ENTITY TYPE linked with itself also called recursive relationship. Example, Roommate, ‘ where STUDENT is linked with STUDENT
3. Ternary Relationship:
A Ternary relationship is the one that involves three entities e.g. STUDENT-CLASS-FACULTY.
Question 7.
Explain Chen’s style and Martin’s style of relation.
Answer:
Cardinality specifies how many instances of an entity relate to one instance of another entity i.e., it specifies the occurrences of relationship and also specifies the maximum number of relationships.
The cardinality notation can be shown using Information Engineering style, Bachman style, Chen style and Martin style.
| Chen Style | |
| One to zero or more | 1:N (n=0,1,2,3..) |
| Zero or more to zero or more | M : N (m and n=0,l,2,3…) |
| One to one. | 1:1 |
| Martin Style | |
| One, and only one (mandatory) | 1 |
| Many (zero or more (optional) | * * |
| One or more (mandatory) | 1.:.* |
| Zero or one (optional) | 0….1 |
| Zero or one (optional) | (0,1) |
| C.,e or more (mandatory) | (l,n) |
| Zero or more (optional) | (0,n) |
| One and only one (mandatory) | (1,1) |
Question 8.
Explain physical data independence.
Answer:
Application programs must remain unchanged when any changes are made in storage representation or access methods. All schemas are logical and actual date is stored in bit format on the disk. Physical data independence is the power to change the physical data without impacting the schema or logical data.
For example, in case we want to change or upgrade the storage system itself, that is, using SSD instead of Hard-disks should not have any impact on logical data or schemas.
![]()
Question 9.
Explain ISAM with example.
Answer:
This method combines both the feature of the sequential and random organizations. Records are accessed by using an index or a table. The index stores the address of each record corresponding to key number of the record. The records within the file are stored sequentially but directly accessed to individual records.
A indexed sequential access method (ISAM) consists of
- The main file storage
- A table to maintain the index
An example is illustrated. Using this table (or index, directory), we can find out the address of any record, given the key value. For example, the record with key equal to ‘00120’ has the address “1”.

Question 10.
Explain database users.
Answer:
There are different types of database users. They are
1. Application programmers or Ordinary users:
These users write application programs to interact with the database. Application programs can be written in some programming language typically a SQL statement to DBMS.
2. End Users:
End users are the users, who use the applications developed. They just use the system to get their task done. End users are of two types:
- Direct users
- Indirect users
3. Database Administrator (DBA):
Database Administrator (DBA) is the person which makes the strategic and policy decisions regarding the data of the enterprise, DBA is responsible for overall control of the system at a technical level.
4. System Analyst:
System Analyst determines the requirement of end-users, and develops specifications for transactions that meet these requirements. System Analyst plays a major role in database design, technical aspect etc. of the system.
Question 11.
Explain the hierarchical data model.
Answer:
The Hierarchical Data Model is created by IBM. It is a way of organizing a database with multiple one to many relationships. The structure is based on the rule that one parent can have many children but children are allowed only one parent.
Advantages:
- allows easy addition and deletion of new information.
- Data at the top of the Hierarchy is very fast to access.
- It relates well to anything that works through a one to many relationships.
Disadvantages:
- It requires data to be repetitively stored in many different entities.
- The database can be very slow when searching for information on the lower entities.
- Searching for data requires the DBMS to run through the entire model, making queries very slow. Can only model
one to many relationships, many to many relationships are not supported.
![]()
Question 12.
Explain the relational data model.
Answer:
Relational Database Model:
Dr. E.F.Codd first introduced the Relational Database Model in 1970. This model allows data to be represented in a ‘simple row-column format’.
Properties of the relational database model:
- Data is presented as a collection of relations.
- Each relation is depicted as a table.
- Columns are attributes that belong to the entity modeled by the table (ex. In a student table, you could have a name, address, student ID, major, etc.).
- Each row (“tuple”) represents a single entity.
- Every table has a set of attributes that taken together as a “key” (technically, a superkey”) uniquely identifies each entity.
Question 13.
Explain outer join with example.
Answer:
JOINS are used to retrieve data from multiple tables. Outer joins are used to return all rows from at least one of the tables. All rows are retrieved from the left table referenced with a left outer join, and all rows from the right table referenced in a right outer join. All rows from both tables are returned in a full outer join.
The three forms of the outer join.
- LEFT OUTER JOIN or LEFT JOIN
- RIGHT OUTER JOIN or RIGHT JOIN
- FULL OUTER JOIN or FULL JOIN
1. LEFT OUTER JOIN:
This type of join returns all rows from the LEFT-hand table specified in the ON condition and only those rows from the other table where the joined fields are equal.
Visual Illustration:
In this visual diagram, the LEFT OUTER JOIN returns the shaded area:
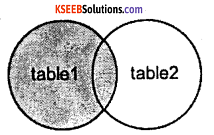
The LEFT OUTER JOIN would return the all records from table 1 and only those records from table2 that intersect with table 1
2. RIGHT OUTER JOIN:
This type of join returns all rows from the RIGHT-hand table specified in the ON condition and only those rows from the other table where the joined fields are equal.
Visual Illustration:
In this visual diagram, the RIGHT OUTER JOIN returns the shaded area:
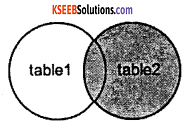
The RIGHT OUTER JOIN would return the all records from table2 and only those records from table 1 that intersect with table2.
3. FULL OUTER JOIN:
This type of join returns all rows from the LEFT-hand table and RIGHT-hand table with nulls in place where the join condition is not met.
Visual Illustration:
In this visual diagram, the FULL OUTER JOIN returns the shaded area:
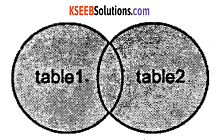
The FULL OUTER JOIN would return the all records from both table1 and table2.
Question 14.
List the components of data warehouse.
Answer.
The components of data warehouse are data sources, data transformation, reporting, metadata, operations and operational components.
In short, data is moved from databases used in operational systems into a data warehouse staging area, then into a data warehouse and finally into a set of conformed data marts. Data is copied from one database to another using a technology called ETL (Extract, Transform, Load).
2nd PUC Computer Science Data Concepts Five Mark Questions and Answers
Question 1.
Explain data processing cycle.
Answer:
DATA PROCESSING CYCLE:
Data processing is the activity of collecting the data from various sources, properly organizing and processing to obtain required information.
The stages of data processing cycle
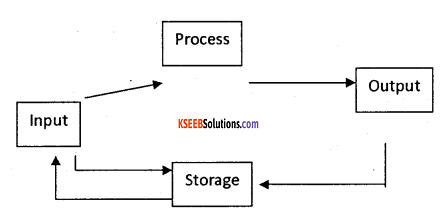
a. Data collection:
Data required for an organization may be available at various places. It involves identifying the source of data for collection. The sources may include documents, such as invoices, sales orders, purchase orders etc., for the purpose of processing.
b. Data input:
The gathered/collected data is entered into the system in the suitable format which is acceptable by the data processing system for the necessary process.
c. Processing of data:
Before any process is applied, classifying the data or grouping the similar type of data is performed. Then to such data proper arrangement/order is done i.e., in ascending or in descending order. Then verification for any missing data, incomplete data is done. Finally calculation process gives the information.
d. Data output:
It is necessary to put the results in proper format in the form of a summarized report, consolidated report, statements etc.,
e. Data storage:
The inputted data and generated results are stored for the future use. They are stored using different mass storage devices (Hard disk, floppy dis, etc.,).
![]()
Question 2.
Explain normalization with classifications and examples.
Normalization
Answer:
Normalization theory is built around the concept of normal forms. Normalization reduces redundancy. Normalization theory is based on the fundamental notion of Functional Dependency. Normalization helps in simplifying the structure of tables.
There are four levels of normalization.
1. First Normal Form:
For easier understanding of the first normal form, consider an example. One employee has different project codes. Hence the projcode is said to be functionally dependent on the attribute Ecode. Now consider an unnormalized data that is represented in the following Table.
A relational model does not permit or support such unnormalized tables. The data table must be present atleast in the first normal form, which appears as shown below.
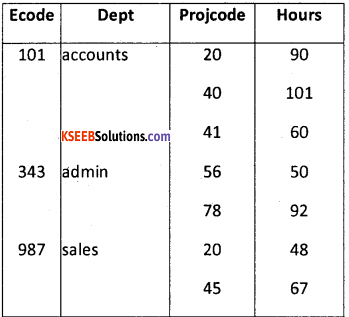
2. Second Normal Form:
In the previous normal form it was noted that there was redundancy of data, and hence the table was decomposed without any loss of information. The problems encountered here were:
Insertion:
Employee details cannot be recorded until the employee is assigned a project.
Updation:
The employee code and department is repeated. Hence if an employee is transferred to another department, these changes must be reflected everywhere. Any omission will lead to inconsistencies.
Deletion:
If any employee completes his project, his record will be deleted and details pertaining to that employee lost.
From the table given below easier understanding is enabled:
It should be noted that for a table to be in the second form it should also be in the first normal
| Encode | Dept |
| 101 | Accounts |
| 343 | Admin |
| 987 | sales |
| Encode | Projcode | Hours |
| 101 | 20 | 90 |
| 101 | 40 | 101 |
| 101 | 41 | 60 |
| 343 | 56 | 50 |
| 343 | 78 | 92 |
| 987 | 20 | 48 |
| 987 | 45 | 67 |
form and every attribute in the record should functionally depend on the primary key.
3. Third Normal Form:
A table is said to be in the third normal form if it is in second normal form and every non-key attribute is functionally dependent on just the primary key: The primary key here is Encode. The attribute dept-code is dependent on the dept. There is an indirect dependence on the primary key, which has to be noticed.
| Encode | Dept | Dept-code |
| 101 | Finance | 909 |
| 303 | Sales | 906 |
| 400 | Sales | 906 |
| 500 | Admin | 908 |
| 600 | Systems | 901 |
| 111 | Finance | 909 |
Even here it was noted that there were problems during insertion, updating and deletion. The relation is thus reduced as shown in the following table.
Each non-key attribute is. wholly dependent only on the primary key. Even the third normal form did not satisfy the needs, Hence, a new form called the BoycecCodd Normal Form was introduced.
4. Boyce-Codd Normal Form:
The third normal form was not satisfactory for relations that had multiple candidate keys. Hence Boyce and Codd introduced another form.
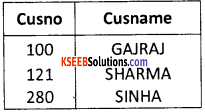
Here the candidate keys are cut code and username. The attribute cut code and username are unique for each row. Consider that another table that has a few other details, as shown in the following Table.
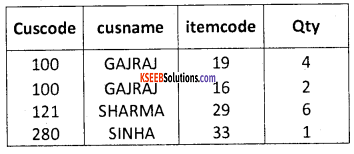
The attributes cuscode and cusname of the above two tables can be used to link these tables. These act as a foreign key in the second table. These tables can be reduced in order to minimize redundancy. The tables are shown below.
| Cuscode | Intemcode | Qty |
| 100 | 19 | 4 |
| 100 | 16 | 2 |
| 121 | 29 | 6 |
| 280 | 33 | 1 |
| Cuscode | Cusname |
| 100 | GAJRAJ |
| 121 | SHARMA |
| 280 | SINHA |
Question 3.
Explain cardinality with example.
Answer:
Cardinality specifies how many instances of an entity relate to one instance of another entity i.e., it specifies the occurrences of the relationship and also specifies the maximum number of relationships. The ordinality describes the relationship as either mandatory or optional.
When the minimum number is zero, the relationship is usually called optional and when the minimum number is one or more, the relationship is usually called mandatory. The cardinality notation can be shown using Information Engineering style, Bachman style, Chen style and Martin style.
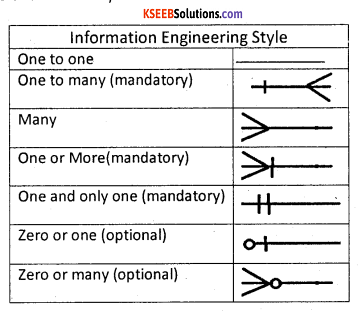

| Chen Style | |
| One to zero or more | 1:N (n-0,1,2,3 ..) |
| Zero or more to zero or more | M : N (m and n=0,l,2,3…) |
| One to one | 1:1 |
| Martin Style | |
| One, and only one (mandatory) | 1 |
| Many (zero or more (optional) | * |
| One or more (mandatory) | 1…* |
| Zero or one (optional) | 0….1 |
| Zero or one (optional) | (0,1) |
| One or more (mandatory) | (1,n) |
| Zero or more (optional) | (0,n) |
| One and only one (mandatory) | (14) |
Question 4.
Explain data independence in detail.
Answer:
Database systems are designed in multi-layers. Data about data itself is divided in layered architecture. A major objective for three-level architecture is to provide data independence, which means that upper levels are unaffected by changes in lower levels.
There are two kinds of data independence:
- Logical data independence
- Physical data independence
1. Logical Data independence:
Logical data independence indicates that the conceptual schema can be changed without affecting the existing external schemas. The change would be absorbed by the mapping between the external and conceptual levels.
Logical data independence also insulates application programs from operations such as combining two records into one or splitting an existing record into two or more records. This would require a change in the external/ conceptual mapping so as to leave the external view unchanged.
2. Physical Data Independence:
Physical data independence indicates that the physical storage structures or devices could be changed without affecting conceptual schema. The change would be absorbed by the mapping between the conceptual and internal levels.
Physical data independence is achieved by the presence of the internal level of the database and the n, IPping or transformation from the conceptual level of the database to the internal level. Conceptual level to internal level mapping, therefore provides a means to go from the conceptual view (conceptual records) to the internal view and hence to the stored data in the database (physical records).
If there is a need to change the file organization or the type of physical device used as a result of growth in the database or new technology, a change is required in the conceptual/ internal mapping between the conceptual and internal levels.
This change is necessary to maintain the conceptual level invariant. The physical data independence criterion requires that the conceptual level does not specify storage structures or the access methods (indexing, hashing etc.) used to retrieve the data from the physical storage medium.
Making the conceptual schema physically data-independent means that the external schema, which is defined on the conceptual schema, is in turn physically data independent.
The Logical data independence is difficult to achieve than physical data independence as it requires the flexibility in the design of database and prograll1iller has to foresee the future requirements or modifications in the design.
![]()
Question 5.
Discuss file organisation with respect to physical data independence.
Answer:
All schemas are logical and actual data is stored in bit format on the disk. Physical data independence is the power to change the physical data without impacting the schema or logical data.
1. Physical file organization:
This organization sees a file as organized and stored in secondary storage media. It depends on the kind of secondary storage device used. If the magnetic tap drive is used then file is organized and accessed sequentially. If the hard disk is used, then the file is stored and accessed randomly or directly. The file manager of the operating system performs this operation.
2. Sequential or serial organization:
In sequential access, records within a file are read or written in sequential order i.e., in the same order they are organized in the file.
In sequential or serial access, the information can be retrieved in the same sequence in which it is stored. The data records are arranged one after the other. The records are stored on the basis of order of the record.
In sequential organization, the data records are stored in a predetermined order based on the key fields. There is a definite relationship between logical position and physical position. The key field organizes the records.
For ex:

Here, the regno is key field. All the records are organized on the key field regno in ascending order. If a regno 124 is to be accessed, then we well have to go through all the previously stored records. A magnetic tape is the most common storage device used to implement sequential and serial file organization.
Advantages:
- file organization is simple
- a data processing which requires the use of all the records is best suited to use this method. For ex: Batch processing
- the magnetic tapes are relatively cheap and reliable
Disadvantages:
- It is not suitable if the file activity ration is low
- Duplication of data is more
- Data transfer rate is slow
- Not suitable for on-line and real-time systems.
Direct Access or Random organization:
A record is accessed by going straight to the record by means of a predefined algorithm. The algorithm calculates the record physical location. The information can be retrieved in a more direct or immediate manner. Access to the information stored is directly by its record key and immediate.
It is possible to access a particular record without going through any order. Many algorithms are used to organize the records.
A common technique is the “hashing technique”. It has two portions. Namely
1. Hashing function:
It is an expression or formula used to generate a physical storage address for a record key.
2. Conflict resolution function:
Takes care of any conflicts which may arise when two record keys are located on a single physical storage location.
The random organisation is implemented in random access devices only like hard disk, CD ROM etc.
Advantages:
- Direct access to any record .
- Faster data access or retrieval.
- Any process to the records need not be arranged in any order
- On-line processing is suited.
- Updating several files can be done.
Disadvantages:
- random access devices are expensive
- uses complex technique
- can not be implemented in magnetic tape.
Indexed Sequential Access Method (ISAM):
This method combines both the feature of the sequential and random organization. Records are accessed by using an index or a table. The index stores the address of each record corresponding to key number of the record. The records within the file are stored sequentially but directly accessed to individual records.
An indexed sequential access method (ISAM) consists of
1. the main file storage
2. A table to maintain the index
Advantages:
- It combines both sequential and direct
- Suitable for sequential access and random access
- Provides quick access to records
Disadvantage:
- it uses special software and is expensive
- extra time is taken to maintain an index
- extra storage for index files
- expensive hardware is required
![]()
Question 6.
Explain the features of the database system.
Answer:
The database management system has promising potential advantages, which are explained below:
1. Controlling Redundancy:
In file system, each application has its own private files, which cannot be shared between multiple applications. This can often lead to considerable redundancy in the stored data, which results in wastage of storage space. By having a centralized database most of this can be avoided.
It is not possible that all redundancy should be eliminated. Sometimes there are sound business and technical reasons for- maintaining multiple copies of the same data. In a database system, however this redundancy can be controlled.
For example:
In case of college database, there may be a number of applications like General Office, Library, Account Office, Hostel etc. Each of these applications may maintain the following information into own private file applications:
It is clear from the above file systems, that there is some common data of the student which has to be mentioned in each application, like Rollno, Name, Class, Phone_No~ Address etc. This will cause the problem of redundancy which results in wastage of storage space and difficult to maintain, but in case of centralized database, data can be shared by number of applications and the whole college can maintain its computerized data with the following database:
It is clear in the above database that Rollno, Name, Class, Father_Name, Address, Phone_No, Date_of_birth which are stored repeatedly in file system in each application, need not be stored repeatedly in case of database, because every other application can access this information by joining of relations on the basis of common column i.e. Rollno. Suppose any user of Library system need the Name, Address of any particular student and by joining of Library and General Office relations on the basis of column Rollno he/she can easily retrieve this information.
Thus, we can say that centralized system of DBMS reduces the redundancy of data to great extent but cannot eliminate the redundancy because RolINo is still repeated in all the relations.
2. Integrity can be enforced:
Integrity of data means that data in database is always accurate, such that incorrect information cannot be stored in database. In order to maintain the integrity of data, some integrity constraints are enforced on the database. A DBMS should provide capabilities for defining and enforcing the constraints.
For Example:
Let us consider the case of college database and suppose that college having only BTech, MTech, MSc, BCA, BBA and BCOM classes. But if a ser enters the class MCA, then this incorrect information must not be stored in database and must be prompted that this is an invalid data entry. In order to enforce this, the integrity constraint must be applied to the class attribute of the student entity. But, in case of file system tins constraint must be enforced on all the application separately (because all applications have a class field).
In case of DBMS, this integrity constraint is applied only once on the class field of the General Office (because class field appears only once in the whole database), and all other applications will get the class information about the student from the General Office table so the integrity constraint is applied to the whole database. So, we can conclude that integrity constraint can be easily enforced in centralized DBMS system as compared to file system.
3. Inconsistency can be avoided :
When the same data is duplicated and changes are made at one site, which is not propagated to the other site, it gives rise to inconsistency and the two entries regarding the same data will not agree. At such times the data is said to be inconsistent. So, if the redundancy is removed chances of having inconsistent data is also removed.
Let us again, consider the college system and suppose that in case of General_Office file it is indicated that Roll_Number 5 lives in Amritsar but in library file it is indicated that Roll_Number 5 lives in Jalandhar. Then, this is a state at which tile two entries of the same object do not agree with each other (that is one is updated and other is not). At such time the database is said to be inconsistent.
An inconsistent database is capable of supplying incorrect or conflicting information. So there should be no inconsistency in database. It can be clearly shown that inconsistency can be avoided in centralized system very well as compared to file system .
Let us consider again, the example of college system and suppose that RolINo 5 is .shifted from Amritsar to Jalandhar, then address information of Roll Number 5 must be updated, whenever Roll number and address occurs in the system. In case of file system, the information must be updated separately in each application, but if we make updation only at three places and forget to make updation at fourth application, then the whole system show the inconsistent results about Roll Number 5.
In case of DBMS, Roll number and address occurs together only single time in General_Office table. So, it needs single updation and then an other application retrieve the address information from General_Office which is updated so, all application will get the current and latest information by providing single update operation and this single update operation is propagated to the whole database or all other application automatically, this property is called as Propagation of Update.
We can say the redundancy of data greatly affect the consistency of data. If redundancy is less, it is easy to implement consistency of data. Thus; DBMS system can avoid inconsistency to great extent.
4. Data can be shared:
As explained earlier, the data about Name, Class, Father name etc. of General_Office is shared by multiple applications in centralized DBMS as compared to file system so now applications can be developed to operate against the same stored data. The applications may be developed without having to create any new stored files.
5. Standards can be enforced :
Since DBMS is a-central system, so standard can be enforced easily may be at Company level, Department level, National level or International level. The standardized data is very helpful during migration or interchanging of data. The file system is an independent system so standard cannot be easily enforced on multiple independent applications.
6. Restricting unauthorized access:
When multiple users share a database, it is likely that some users will not be authorized to access all information in the database. For example, account office data is often considered confidential, and hence only authorized persons are allowed to access such data. In addition, some users may be permitted only to retrieve data, whereas other are allowed both to retrieve and to update.
Hence, the type of access operation retrieval or update must also be controlled. Typically, users or user groups are given account numbers protected by passwords, which they can use to gain access to the database. A DBMS should provide a security and authorization subsystem, which the DBA uses to create accounts and to specify account restrictions. The DBMS should then enforce these restrictions automatically.
7. Solving Enterprise Requirement than Individual Requirement:
Since many types of users with varying level of technical knowledge use a database, a DBMS should provide a variety of user interface. The overall requirements of the enterprise are more important than the individual user requirements. So, the DBA can structure the database system to provide an overall service that is “best for the enterprise”.
For example: A representation can be chosen for the data in storage that gives fast access for the most important application at the cost of poor performance in some other application. But, the file system favors the individual requirements than the enterprise requirements
8. Providing Backup and Recovery:
A DBMS must provide facilities for recovering from hardware or software failures. The backup and recovery subsystem of the DBMS is responsible for recovery. For example, if the computer system fails in the middle of a complex update program, the recovery subsystem is responsible for making sure that the .database is restored to the state it was in before the program started executing.
9. Cost of developing and maintaining system is lower:
It is much easier to respond to unanticipated requests when data is centralized in a database than when it is stored in a conventional file system. Although the initial cost of setting up of a database can be large, but the cost of developing and maintaining application programs to be far lower than for similar service using conventional systems.
The productivity of programmers can be higher in using non-procedural languages that have been developed with DBMS than using procedural languages.
10. Data Model can be developed :
The centralized system is able to represent complex data and interfile relationships, which results in better data modeling properties. The data madding properties of the relational model is based on Entity and their Relationship, which is discussed in detail in chapter 4 of the book.
11. Concurrency Control :
DBMS systems provide mechanisms to provide concurrent access of data to multiple users.
![]()
Question 7.
Explain DBMS architecture.
Answer:
The design of DBMS depends on its architecture. The DBMS architecture can be a single-tier or multi-tier. The dividing the system helps to modify, alter, change or replace on independent ‘n’ modules.
The database architecture is logically classified as
- one-tier architecture
- two-tier architecture
- three-tier architecture
a. Logical one tier architecture:
Here, DBMS is the only entity where DBMS user directly access database and uses it. Any changes made by the user directly done on DBMS itself. The database designers and programmers use 1-tier architecture.
b. Logical two-tier architecture:
It is a client/server architecture where user interface program and application programs run on client side. The ODBC interfaces provide API that allows client side program to call the DBMS. A client program may connect to several DBMS’s.
c. 3-tier architecture:
Most widely used architecture is 3-tier architecture. 3-tier architecture separates it tier from each other on basis of users. It is described as follows:
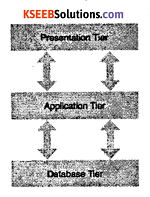
1. Database (Data) Tier:
At this tier, only the database resides. Database along with its query processing languages contains all relations and their constraints.
2. Application (Middle) Tier:
At this tier the application server and program, which access database, resides. Users are unaware of any existence of a database beyond application. For database-tier, the application tier is the user of it. This tier works as mediator between the two.
3. User (Presentation) Tier:
An end user sits on this tier. From a users aspect this tier is everything. He/she doesn’t know about any existence or form of database beyond this layer. All views are generated by applications, which resides in the application tier.
![]()
Question 8.
Explain database model.
Database Models
Answer:
Database models are broadly classified into two categories.
They are:
- Object-based logical models
- Record-based logical models
The object-based logical model can be defined as a collection of conceptual tools for describing data, data relationships, and data constraints.
The record-based model describes the data structures and access techniques of a DBMS. There are three types of record-based logical models. They are the hierarchical model, the network model, and the relational model.
Consider the example of a company. There are many employees who work in various departments earning a different salary. EMPLOYEE, DEPARTMENT, SALARY represents the entities about which data has to be recorded. It would be really meaningless if the data just exists in the database.
Hence it is necessary that these data should be related to each other. Therefore a database should maintain information about these data and relationships.
Hierarchical Database Systems (HDS):
Consider the tree diagram as given below.
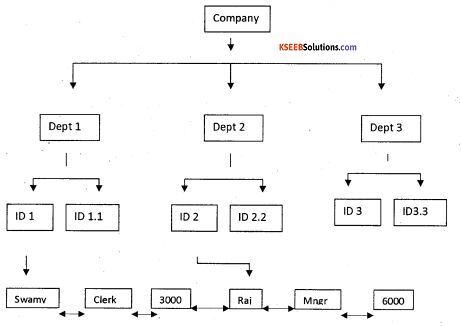
This can be said to have a parent-child relationship. The orgin of a data tree is the root. Data located at different levels along a particular branch from the root is called the node.
The last node in the series is called the leaf. This model supports a One-to-Many relationship. Each child has pointers to numerous siblings and there is just one pointer to the parent thus proving a One-to-Many relationship.
Drawbacks:
It is not possible to insert a new level in the table without altering the structure. Suppose a new level is required between the root and the department, the only alternative is to frame an entirely new structure.
To set this relationship, multiple copies of the same data must be stored at multiple levels that could cause redundancy of data. To overcome this drawback, the Network Database Model was introduced.
Network Database Systems (NDS):
This model comes under Record-based logical model. The main idea behind this model is to bring about a Many-to-Many relationship. The relationship between the different data items is called as the sets. This system also uses a pointer to locate a particular record. Let us consider the item – vendor example as shown.
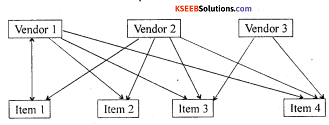
If one has to know which vendor(s) is selling a particular item or which particular item the vendor sells, it is completely dependent on the pointer to map out the relationship. But even here in case of large volumes of data, it is very difficult to locate the item because it will increase the complexity as it uses pointers, the mapping of data would become very difficult.
Since all the models use pointers it increases complexity. To overcome all the drawbacks the idea of a Relational Database System came up.
Relational Database Model:
Dr. E.F.Codd first introduced the Relational Database Model in 1970. This model allows data to be represented in a ‘simple row-column format’. Each data field is considered as a column and each record is considered as a row of a table. Different relationships between the various tables are achieved by mathematical set functions namely JOIN and UNION.
Question 9.
Explain Codd’s rules for database management.
Answer:
Dr. Edgar Frank Codd was a computer scientist while working for IBM he invented the relational model for database management. Codd.proposed thirteen rules (numbered zero to twelve) and said that if a Database Management System meets these rules, it can be called as a Relational Database Management System. These rules are called as Codd’s12 rules.
Rule Zero:
- The system must qualify as relational, as a database, and as a management system. For a system to qualify as a relational database management system (RDBMS), that system must use its relational facilities (exclusively) to manage the database.
- The other 12 rules derive from this rule. The rules are as follows :
Rule 1:
The information rule:
All information in the database is to be represented in one and only one way, namely by values in column positions within rows of tables.
Rule 2:
The guaranteed access rule:
All data must be accessible. This rule is essentially a restatement of the fundamental requirement for primary keys. It says that every individual value in the database must be logically addressable by specifying table name, column name and the primary key value of the row.
Rule 3:
Systematic treatment of null values:
The DBMS must allow each field to remain null (or empty). The NULL can be represented as “missing information and inapplicable information” that is systematic, distinct from all regular values, and independent of data type. Such values must be manipulated by the DBMS in a systematic way.
Rule 4:
Active online catalog based on the relational model:
The system must support an online, inline, relational catalog that is accessible to authorized users by means of their regular query language
Rule 5:
The comprehensive data sublanguage rule:
The system must support at least one relational language that
- Has a linear syntax
- Can be used both interactively and within application programs,
- Supports data definition operations, data manipulation operations, security and integrity constraints, and transaction management operations.
Rule 6:
The view updating rule:
All views that can be updated theoretically must be updated by the system.
Rule 7:
High-level insert, update, and delete:
This rule states that insert, update, and delete operations should be supported for any retrievable set rather than just for a single row in a single table.
Rule 8:
Physical data independence:
Changes to the physical level (how the data is stored, whether in arrays or linked lists etc.) must not require a change to an application based on the structure.
Rule 9:
Logical data independence:
Changes to the logical level (tables, columns, rows, and so on) must not require a change to an application based on the structure.
Rule 10:
Integrity independence:
Integrity constraints must be specified separately from application programs and stored in the catalog. It must be possible to change such constraints as and when appropriate without unnecessarily affecting existing applications.
Rule 11:
Distribution independence:
The distribution of portions of the database to various locations should be invisible to users of the database. Existing applications should continue to operate successfully.
Rule 12:
The non-subversion rule:
If the system provides a low-level (record-at-a-time) interface, then that interface cannot be used to subvert the system, for example, bypassing a relational security or integrity constraint